一、gzip介绍
Gzip是一种流行的文件压缩算法,现在的应用十分广泛,尤其是在Linux平台。当应用Gzip压缩到一个纯文本文件时,效果是非常明显的,大约可以减少70%以上的文件大小。这取决于文件中的内容。
利用Apache中的Gzip模块,我们可以使用Gzip压缩算法来对Apache服务器发布的网页内容进行压缩后再传输到客户端浏览器。这样经过压缩后实际上降低了网络传输的字节数,最明显的好处就是可以加快网页加载的速度。
网页加载速度加快的好处不言而喻,除了节省流量,改善用户的浏览体验外,另一个潜在的好处是Gzip与搜索引擎的抓取工具有着更好的关系。例如 Google就可以通过直接读取gzip文件来比普通手工抓取更快地检索网页。在Google网站管理员工具(Google Webmaster Tools)中你可以看到,sitemap.xml.gz 是直接作为Sitemap被提交的。
而这些好处并不仅仅限于静态内容,PHP动态页面和其他动态生成的内容均可以通过使用Apache压缩模块压缩,加上其他的性能调整机制和相应的服务器端 缓存规则,这可以大大提高网站的性能。因此,对于部署在Linux服务器上的PHP程序,在服务器支持的情况下,我们建议你开启使用Gzip Web压缩。
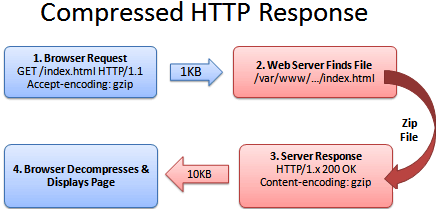
二、Web服务器处理HTTP压缩的过程如下:
1. Web服务器接收到浏览器的HTTP请求后,检查浏览器是否支持HTTP压缩(Accept-Encoding 信息);
2. 如果浏览器支持HTTP压缩,Web服务器检查请求文件的后缀名;
3. 如果请求文件是HTML、CSS等静态文件,Web服务器到压缩缓冲目录中检查是否已经存在请求文件的最新压缩文件;
4. 如果请求文件的压缩文件不存在,Web服务器向浏览器返回未压缩的请求文件,并在压缩缓冲目录中存放请求文件的压缩文件;
5. 如果请求文件的最新压缩文件已经存在,则直接返回请求文件的压缩文件;
6. 如果请求文件是动态文件,Web服务器动态压缩内容并返回浏览器,压缩内容不存放到压缩缓存目录中。
下面是两个演示图:
未使用Gzip:
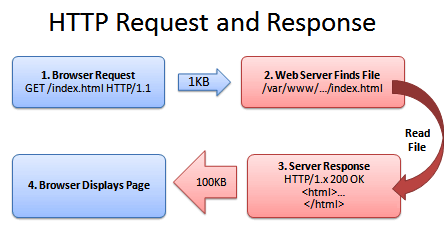
开启使用Gzip后:
三、实施
Apache上利用Gzip压缩算法进行压缩的模块有两种:mod_gzip 和mod_deflate。 要使用Gzip Web压缩,请首先确定你的服务器开启了对这两个组件之一的支持。在Linux服务器上,现在已经有越来越多的空间商开放了对它们的支持,有的甚至是同时 支持这两个模块的。例如目前Godaddy、Bluehost及DreamHosts等空间商的服务器都已同时支持mod_gzip 和mod_deflate。
虽然使用Gzip同时也需要客户端浏览器的支持,不过不用担心,目前大部分浏览器都已经支持Gzip了,如IE、Mozilla Firefox、Opera、Chrome等。
通过查看HTTP头,我们可以快速判断使用的客户端浏览器是否支持接受gzip压缩。若发送的HTTP头中出现以下信息,则表明你的浏览器支持接受相应的gzip压缩:
Accept-Encoding: gzip 支持mod_gzip
Accept-Encoding: deflate 支持mod_deflate
Accept-Encoding: gzip,deflate 同时支持mod_gzip 和mod_deflate 在apache2.0以上(包括apache2.0)的版中gzip压缩使用的是mod_deflate模块,下面是具体配置步骤 如下:
1、修改Apache的http.conf文件,去除mod_deflate.so前面的注释
LoadModule deflate_module modules/mod_deflate.so
2、在根目录中新建.htaccess文件,定制压缩规则
#GZIP压缩模块配置
<ifmodule mod_deflate.c>
#启用对特定MIME类型内容的压缩
SetOutputFilter DEFLATE
SetEnvIfNoCase Request_URI .(?:gif|jpe?g|png|exe|t?gz|zip|bz2|sit|rar|pdf|mov|avi|mp3|mp4|rm)$ no-gzip dont-vary #设置不对压缩的文件
AddOutputFilterByType DEFLATE text/html text/css text/plain text/xml application/x-httpd-php application/x-javascript #设置对压缩的文件
</ifmodule>
3、对指定的文件配置缓存的生存时间,去除mod_headers.so模块前面的注释
LoadModule headers_module modules/mod_headers.so
4、在根目录中新建.htaccess文件,定制压缩规则
#文件缓存时间配置
<FilesMatch “.(flv|gif|jpg|jpeg|png|ico|swf|js|css)$”>
Header set Cache-Control “max-age=2592000”
</FilesMatch>
里面的文件MIME类型可以根据自己情况添加,至于PDF 、图片、音乐文档之类的这些本身都已经高度压缩格式,重复压缩的作用不大,反而可能会因为增加CPU的处理时间及浏览器的渲染问题而降低性能。所以就没必要再通过Gzip压缩。通过以上设置后再查看返回的HTTP头,出现以下信息则表明返回的数据已经过压缩。即网站程序所配置的Gzip压缩已生效。
Content-Encoding: gzip注:不管使用mod_gzip 还是mod_deflate,此处返回的信息都一样。因为它们都是实现的gzip压缩方式。
除此之外,还可以通过一些在线检查工具http://tool.chinaz.com/Gzips/来检测你的网站内容是否已经过Gzip压缩。
四、mod_gzip 和mod_deflate的主要区别是什么?使用哪个更好呢?
首先一个区别是安装它们的Apache Web服务器版本的差异。Apache 1.x系列没有内建网页压缩技术,所以才去用额外的第三方mod_gzip 模块来执行压缩。而Apache 2.x官方在开发的时候,就把网页压缩考虑进去,内建了mod_deflate 这个模块,用以取代mod_gzip。虽然两者都是使用的Gzip压缩算法,它们的运作原理是类似的。
第二个区别是压缩质量。mod_deflate 压缩速度略快而mod_gzip 的压缩比略高。一般默认情况下,mod_gzip 会比mod_deflate 多出4%~6%的压缩量。
那么,为什么使用mod_deflate?第三个区别是对服务器资源的占用。 一般来说mod_gzip 对服务器CPU的占用要高一些。mod_deflate 是专门为确保服务器的性能而使用的一个压缩模块,mod_deflate 需要较少的资源来压缩文件。这意味着在高流量的服务器,使用mod_deflate 可能会比mod_gzip 加载速度更快。
不太明白?简而言之,如果你的网站,每天不到1000独立访客,想要加快网页的加载速度,就使用mod_gzip。虽然会额外耗费一些服务器资源, 但也是值得的。如果你的网站每天超过1000独立访客,并且使用的是共享的虚拟主机,所分配系统资源有限的话,使用mod_deflate 将会是更好的选择。
另外,从Apache 2.0.45开始,mod_deflate 可使用DeflateCompressionLevel 指令来设置压缩级别。该指令的值可为1(压缩速度最快,最低的压缩质量)至9(最慢的压缩速度,压缩率最高)之间的整数,其默认值为6(压缩速度和压缩质 量较为平衡的值)。这个简单的变化更是使得mod_deflate 可以轻松媲美mod_gzip 的压缩。
P.S. 对于没有启用以上两种Gzip模块的虚拟空间,还可以退而求其次使用php的zlib函数库(同样需要查看服务器是否支持)来压缩文件,只是这种方法使用起来比较麻烦,而且一般会比较耗费服务器资源,请根据情况慎重使用。详细 php启用zlib压缩文件